Building Ruby Web Scraper Using Domains-index.com Lists as a Crawling DB
Nowadays there are a bunch of tools/libraries and so on for web scraping, and one of them is Ruby Mechanize Gem, which could be used for it too. We will build a simple script using domains-index.com ccTLD zone file as a crawling list to obtain Titles from the websites. Also, we are going to log access/resolve errors for future analysis. First of all, let’s get one of the free ccTLD lists from domains-index, I’ve chosen Curaçao list, available here:
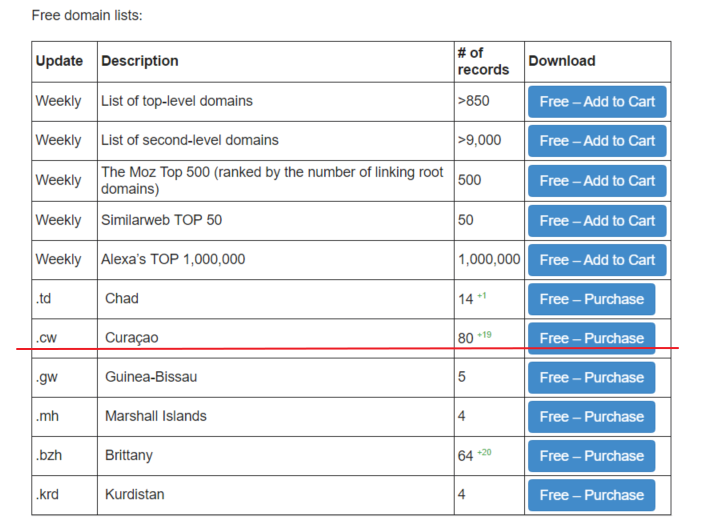
You can choose any other one or even buy one, at this stage it doesn’t matter. After obtaining the list let’s do some ruby coding:
I’m assuming that you have Ruby environment in place, and our tutorial is not about setting up everything from the scratch, so after finishing the script and having a list in the same directory we can start it (Curaçao cw.csv list used as input and cw_titles.csv as output there):
>ruby titles.rb cw.csv cw_titles.csv
You should have some patience because it takes a while. For Curaçao, for example, it took about 20 minutes to finish, the same time it has only 80 domains. As a result, we are getting CSV spreadsheet with three columns Status/URL/Title(Error code) which you can use for future processing/analysis:
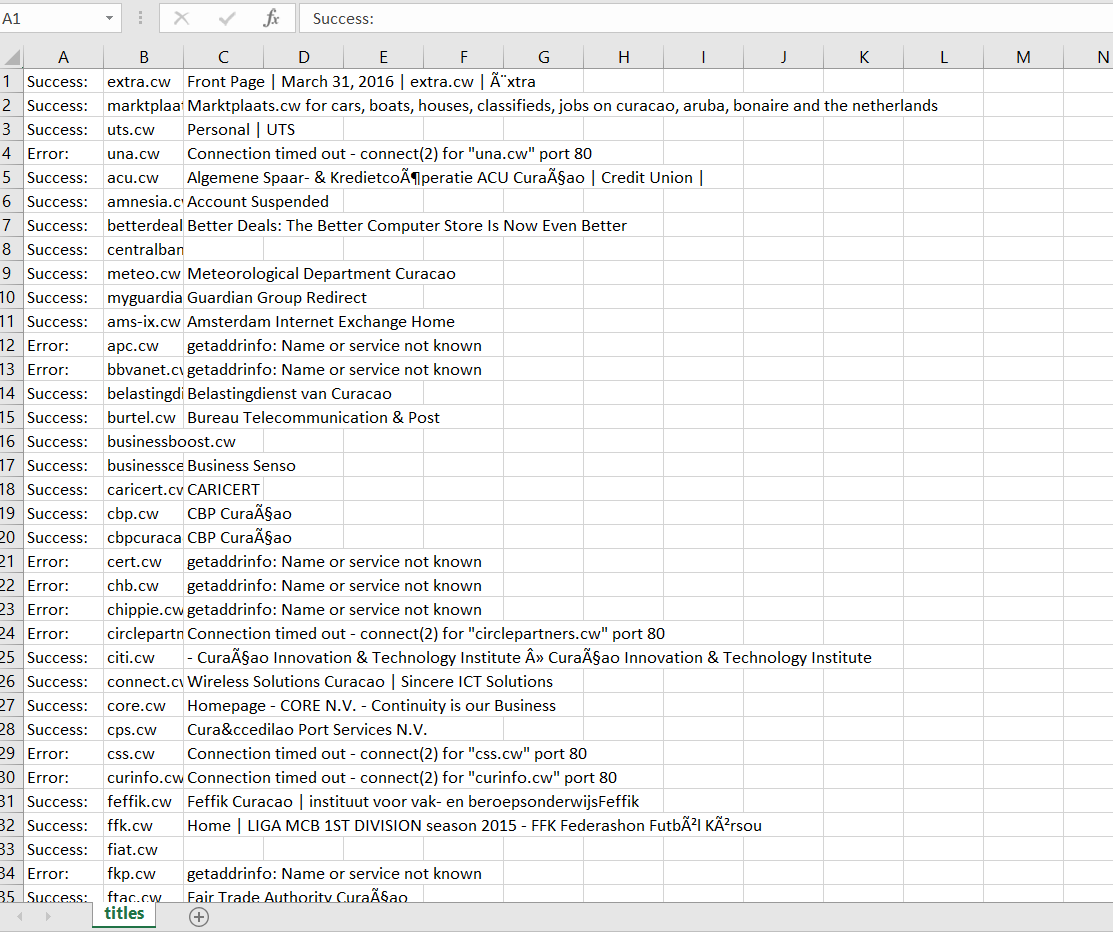
Download titles (Curaçao ccTLD)
Web scraper is not limited to obtaining titles; you can get links, emails, meta key, or whatever you want by customizing Mechanize Gem requests. Titles are just some simple thing, example. Stay in touch and take care!